O、内存相关
-
下列程序为什么会卡死(测试不会被卡死)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
package main
import (
"fmt"
"runtime"
)
func main() {
var i byte
go func() {
for i = 0; i <= 255; i++ {}
}()
fmt.Println("Dropping mic")
// Yield execution to force executing other goroutines runtime.Gosched()
runtime.GC()
fmt.Println("Done")
}
|
解析: Golang 中,byte 其实被 alias 到 uint8 上了。所以上⾯的 for 循环会始终成⽴,因为 i++ 到 i=255 的时候会溢出,i <= 255 ⼀定成⽴。 也即是, for 循环永远⽆法退出,所以上⾯的代码其实可以等价于这样:
go func() { for {} }
正在被执⾏的 goroutine 发⽣以下情况时让出当前 goroutine 的执⾏权,并调度后⾯的 goroutine 执⾏:
- IO 操作
- Channel 阻塞
- system call
- 运⾏较⻓时间
如果⼀个 goroutine 执⾏时间太⻓,scheduler 会在其 G 对象上打上⼀个标志( preempt),当这个 goroutine 内部发⽣函数调⽤的时候,会先主动检查这个标志,如 果为 true 则会让出执⾏权。
main 函数⾥启动的 goroutine 其实是⼀个没有 IO 阻塞、没有 Channel 阻塞、没有 system call、没有函数调⽤的死循环。 也就是,它⽆法主动让出⾃⼰的执⾏权,即使已经执⾏很⻓时间,scheduler 已经标志 了 preempt。 ⽽ golang 的 GC 动作是需要所有正在运⾏ goroutine 都停⽌后进⾏的。因此,程序 会卡在 runtime.GC() 等待所有协程退出。
一、数据定义
(1).函数返回值问题
下面代码是否可以编译通过?
1
2
3
4
5
6
7
8
9
10
11
12
13
|
package main
/*
下面代码是否编译通过?
*/
func myFunc(x,y int)(sum int,error){
return x+y,nil
}
func main() {
num, err := myFunc(1, 2)
fmt.Println("num = ", num)
}
|
答案:
编译报错理由:
1
2
|
# command-line-arguments
./test1.go:6:21: syntax error: mixed named and unnamed function parameters
|
考点:函数返回值命名
结果:编译出错。
在函数有多个返回值时,只要有一个返回值有指定命名,其他的也必须有命名。 如果返回值有有多个返回值必须加上括号; 如果只有一个返回值并且有命名也需要加上括号; 此处函数第一个返回值有sum名称,第二个未命名,所以错误。
(2).结构体比较问题
下面代码是否可以编译通过?为什么?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
package main
import "fmt"
func main() {
sn1 := struct {
age int
name string
}{age: 11, name: "qq"}
sn2 := struct {
age int
name string
}{age: 11, name: "qq"}
if sn1 == sn2 {
fmt.Println("sn1 == sn2")
}
sm1 := struct {
age int
m map[string]string
}{age: 11, m: map[string]string{"a": "1"}}
sm2 := struct {
age int
m map[string]string
}{age: 11, m: map[string]string{"a": "1"}}
if sm1 == sm2 {
fmt.Println("sm1 == sm2")
}
}
|
结果
编译不通过
1
|
./test2.go:31:9: invalid operation: sm1 == sm2 (struct containing map[string]string cannot be compared)
|
考点:结构体比较
结构体比较规则注意1:只有相同类型的结构体才可以比较,结构体是否相同不但与属性类型个数有关,还与属性顺序相关.
比如:
1
2
3
4
5
6
7
8
9
|
sn1 := struct {
age int
name string
}{age: 11, name: "qq"}
sn3:= struct {
name string
age int
}{age:11, name:"qq"}
|
sn3与sn1就不是相同的结构体了,不能比较。
结构体比较规则注意2:结构体是相同的,但是结构体属性中有不可以比较的类型,如map,slice,则结构体不能用==比较。
可以使用reflect.DeepEqual进行比较
1
2
3
4
5
|
if reflect.DeepEqual(sm1, sm2) {
fmt.Println("sm1 == sm2")
} else {
fmt.Println("sm1 != sm2")
}
|
(3).string与nil类型
下面代码是否能够编译通过?为什么?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
package main
import (
"fmt"
)
func GetValue(m map[int]string, id int) (string, bool) {
if _, exist := m[id]; exist {
return "存在数据", true
}
return nil, false
}
func main() {
intmap:=map[int]string{
1:"a",
2:"bb",
3:"ccc",
}
v,err:=GetValue(intmap,3)
fmt.Println(v,err)
}
|
考点:函数返回值类型
答案:编译不会通过。
分析:
nil 可以用作 interface、function、pointer、map、slice 和 channel 的“空值”。但是如果不特别指定的话,Go 语言不能识别类型,所以会报错。通常编译的时候不会报错,但是运行是时候会报:cannot use nil as type string in return argument.
所以将GetValue函数改成如下形式就可以了
1
2
3
4
5
6
|
func GetValue(m map[int]string, id int) (string, bool) {
if _, exist := m[id]; exist {
return "存在数据", true
}
return "不存在数据", false
}
|
(4) 常量
下面函数有什么问题?
1
2
3
4
5
6
7
8
9
10
|
package main
const cl = 100
var bl = 123
func main() {
println(&bl,bl)
println(&cl,cl)
}
|
解析
考点:常量
常量不同于变量的在运行期分配内存,常量通常会被编译器在预处理阶段直接展开,作为指令数据使用,
1
|
cannot take the address of cl
|
内存四区概念:
A.数据类型本质:
固定内存大小的别名
B. 数据类型的作用:
编译器预算对象(变量)分配的内存空间大小。
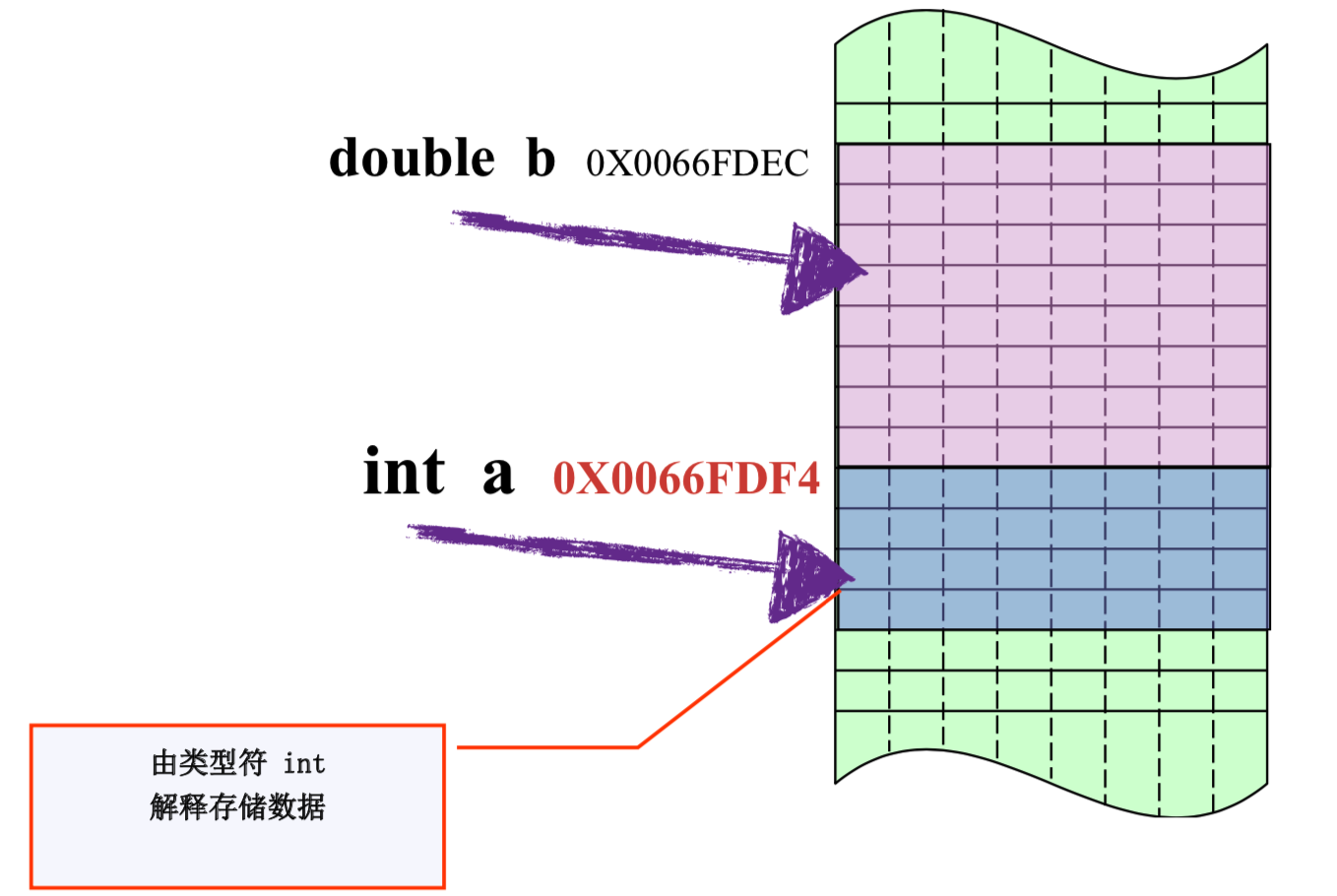
C. 内存四区
流程说明
1、操作系统把物理硬盘代码load到内存
2、操作系统把c代码分成四个区
3、操作系统找到main函数入口执行
栈区(Stack):
- 空间较小,要求数据读写性能高,数据存放时间较短暂。由编译器自动分配和释放,存放函数的参数值、函数的调用流程方法地址、局部变量等(局部变量如果产生逃逸现象,可能会挂在在堆区)
堆区(heap):
- 空间充裕,数据存放时间较久。一般由开发者分配及释放(但是Golang中会根据变量的逃逸现象来选择是否分配到栈上或堆上),启动Golang的GC由GC清除机制自动回收。
全局区-静态全局变量区:
我们尽量减少使用全局变量的设计
全局区-常量区:
所以在golang中,常量是无法取出地址的,因为字面量符号并没有地址而言。
(5) defer练习
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
|
package main
import "fmt"
func DeferFunc1(i int) (t int) {
t = i
defer func() {
t += 3
}()
return t
}
func DeferFunc2(i int) int {
t := i
defer func() {
t += 3
}()
return t
}
func DeferFunc3(i int) (t int) {
defer func() {
t += i
}()
return 2
}
func DeferFunc4() (t int) {
defer func(i int) {
fmt.Println(i)
fmt.Println(t)
}(t)
t = 1
return 2
}
func main() {
fmt.Println(DeferFunc1(1)) // 4
fmt.Println(DeferFunc2(1)) // 1
fmt.Println(DeferFunc3(1)) // 3
DeferFunc4() // 0 2
}
|
二、数组和切片
(1) 切片的初始化与追加
1.1
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
package main
import "fmt"
func main() {
s1 := []int{1, 2, 3}
fmt.Println(len(s1), cap(s1), s1) //输出 3 3 [1 2 3]
s2 := s1[1:] //索引从第二个元素截取开始
fmt.Println(len(s2), cap(s2), s2) //输出 2 2 [2 3]
for i := range s2 {
s2[i] += 20
}
//仍然引用同一数组
fmt.Println(s1) //s1 在s2修改了后面2个元素,所以s1也是更新了。输出 [1 22 23]
fmt.Println(s2) //输出 [22 23]
s2 = append(s2, 4) // 注意s2的容量是2,追加新元素后将导致分配一个新的数组 [22 23 4]
for i := range s2 {
s2[i] += 10
}
//s1 仍然是更新后的历史老数据
fmt.Println(s1) //输出 [1 22 23]
fmt.Println(s2) //输出 [32 33 14]
}
|
1.2 写出程序运行的结果
1
2
3
4
5
6
7
8
9
10
11
12
13
|
package main
import (
"fmt"
)
func main(){
s := make([]int, 10)
s = append(s, 1, 2, 3)
fmt.Println(s)
}
|
考点
切片追加, make初始化均为0
结果
1
|
[0 0 0 0 0 0 0 0 0 0 1 2 3]
|
(2) slice拼接问题
下面是否可以编译通过?
test6.go
1
2
3
4
5
6
7
8
9
10
|
package main
import "fmt"
func main() {
s1 := []int{1, 2, 3}
s2 := []int{4, 5}
s1 = append(s1, s2)
fmt.Println(s1)
}
|
结果
编译失败
两个slice在append的时候,记住需要进行将第二个slice进行...打散再拼接。
(3) slice中new的使用
下面代码是否可以编译通过?
1
2
3
4
5
6
7
8
9
10
11
12
|
package main
import "fmt"
func main() {
list := new([]int)
list = append(list, 1)
fmt.Println(list)
}
|
结果:
编译失败,./test9.go:9:15: first argument to append must be slice; have *[]int
分析:
切片指针的解引用。
可以使用list:=make([]int,0) list类型为切片
或使用*list = append(*list, 1) list类型为指针
new和make的区别:
二者都是内存的分配(堆上),但是make只用于slice、map以及channel的初始化(非零值);而new用于类型的内存分配,并且内存置为零。所以在我们编写程序的时候,就可以根据自己的需要很好的选择了。
make返回的还是这三个引用类型本身;而new返回的是指向类型的指针。
三、Map
(1) Map的Value赋值
下面代码编译会出现什么结果?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
package main
import "fmt"
type Student struct {
Name string
}
var list map[string]Student
func main() {
list = make(map[string]Student)
student := Student{"Aceld"}
list["student"] = student
list["student"].Name = "LDB"
fmt.Println(list["student"])
}
|
结果
编译失败,./test7.go:18:23: cannot assign to struct field list["student"].Name in map
分析
map[string]Student 的value是一个Student结构值,所以当list["student"] = student,是一个值拷贝过程。而list["student"]则是一个值引用。那么值引用的特点是只读。所以对list["student"].Name = "LDB"的修改是不允许的。
方法一:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
package main
import "fmt"
type Student struct {
Name string
}
var list map[string]Student
func main() {
list = make(map[string]Student)
student := Student{"Aceld"}
list["student"] = student
//list["student"].Name = "LDB"
/*
方法1:
*/
tmpStudent := list["student"]
tmpStudent.Name = "LDB"
list["student"] = tmpStudent
fmt.Println(list["student"])
}
|
其中
1
2
3
4
5
6
|
/*
方法1:
*/
tmpStudent := list["student"]
tmpStudent.Name = "LDB"
list["student"] = tmpStudent
|
是先做一次值拷贝,做出一个tmpStudent副本,然后修改该副本,然后再次发生一次值拷贝复制回去,list["student"] = tmpStudent,但是这种会在整体过程中发生2次结构体值拷贝,性能很差。
方法二:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
package main
import "fmt"
type Student struct {
Name string
}
var list map[string]*Student
func main() {
list = make(map[string]*Student)
student := Student{"Aceld"}
list["student"] = &student
list["student"].Name = "LDB"
fmt.Println(list["student"])
}
|
我们将map的类型的value由Student值,改成Student指针。
1
|
var list map[string]*Student
|
这样,我们实际上每次修改的都是指针所指向的Student空间,指针本身是常指针,不能修改,只读属性,但是指向的Student是可以随便修改的,而且这里并不需要值拷贝。只是一个指针的赋值。
(2) map的遍历赋值
以下代码有什么问题,说明原因
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
package main
import (
"fmt"
)
type student struct {
Name string
Age int
}
func main() {
//定义map
m := make(map[string]*student)
//定义student数组
stus := []student{
{Name: "zhou", Age: 24},
{Name: "li", Age: 23},
{Name: "wang", Age: 22},
}
//将数组依次添加到map中
for _, stu := range stus {
m[stu.Name] = &stu
}
//打印map
for k,v := range m {
fmt.Println(k ,"=>", v.Name)
}
}
|
结果
遍历结果出现错误,输出结果为
1
2
3
|
zhou => wang
li => wang
wang => wang
|
map中的3个key均指向数组中最后一个结构体。
分析
foreach中,stu是结构体的一个拷贝副本,所以m[stu.Name]=&stu实际上一致指向同一个指针, 最终该指针的值为遍历的最后一个struct的值拷贝。
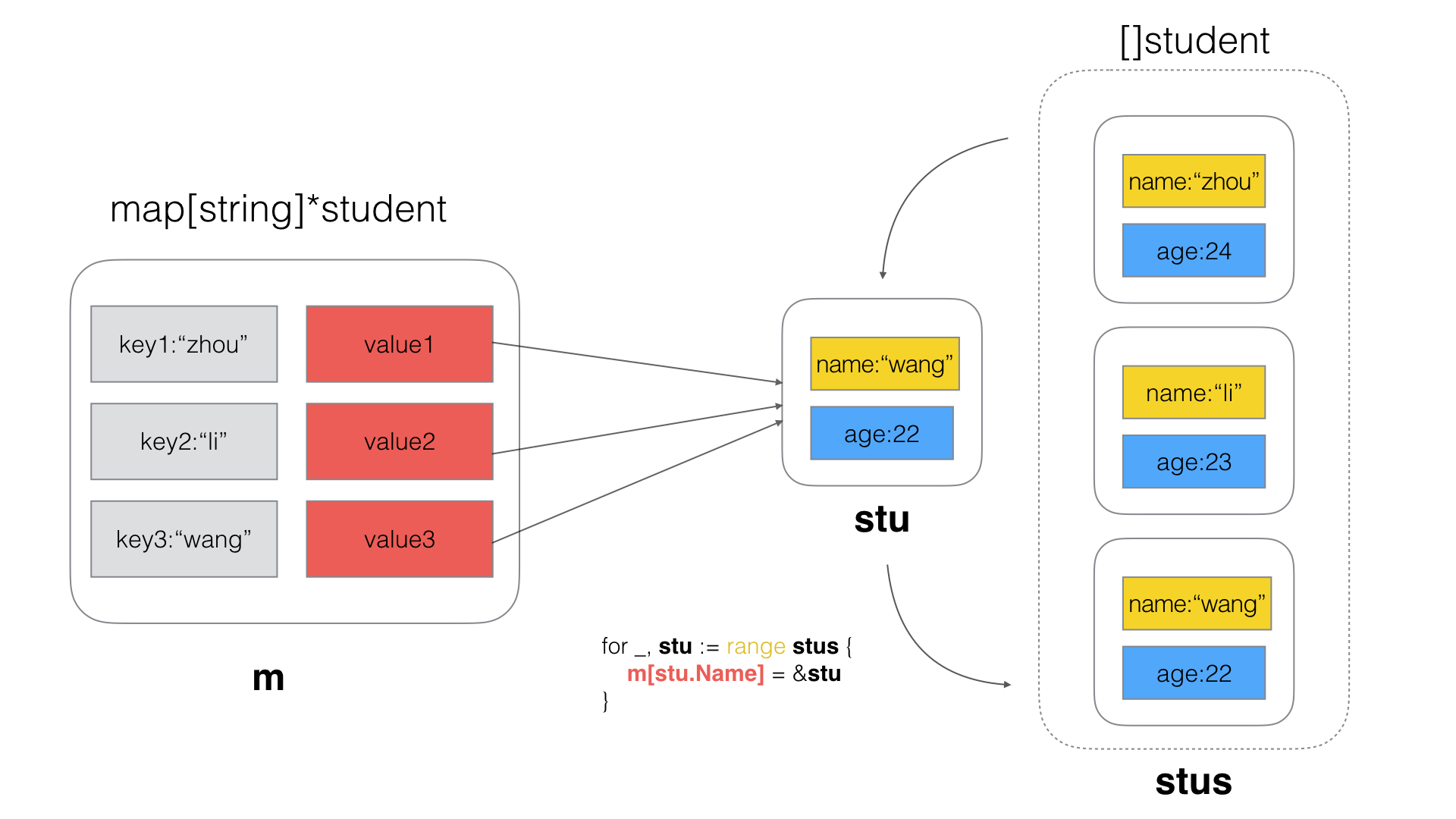
正确写法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
package main
import (
"fmt"
)
type student struct {
Name string
Age int
}
func main() {
//定义map
m := make(map[string]*student)
//定义student数组
stus := []student{
{Name: "zhou", Age: 24},
{Name: "li", Age: 23},
{Name: "wang", Age: 22},
}
// 遍历结构体数组,依次赋值给map
for i := 0; i < len(stus); i++ {
m[stus[i].Name] = &stus[i]
}
//打印map
for k,v := range m {
fmt.Println(k ,"=>", v.Name)
}
}
|
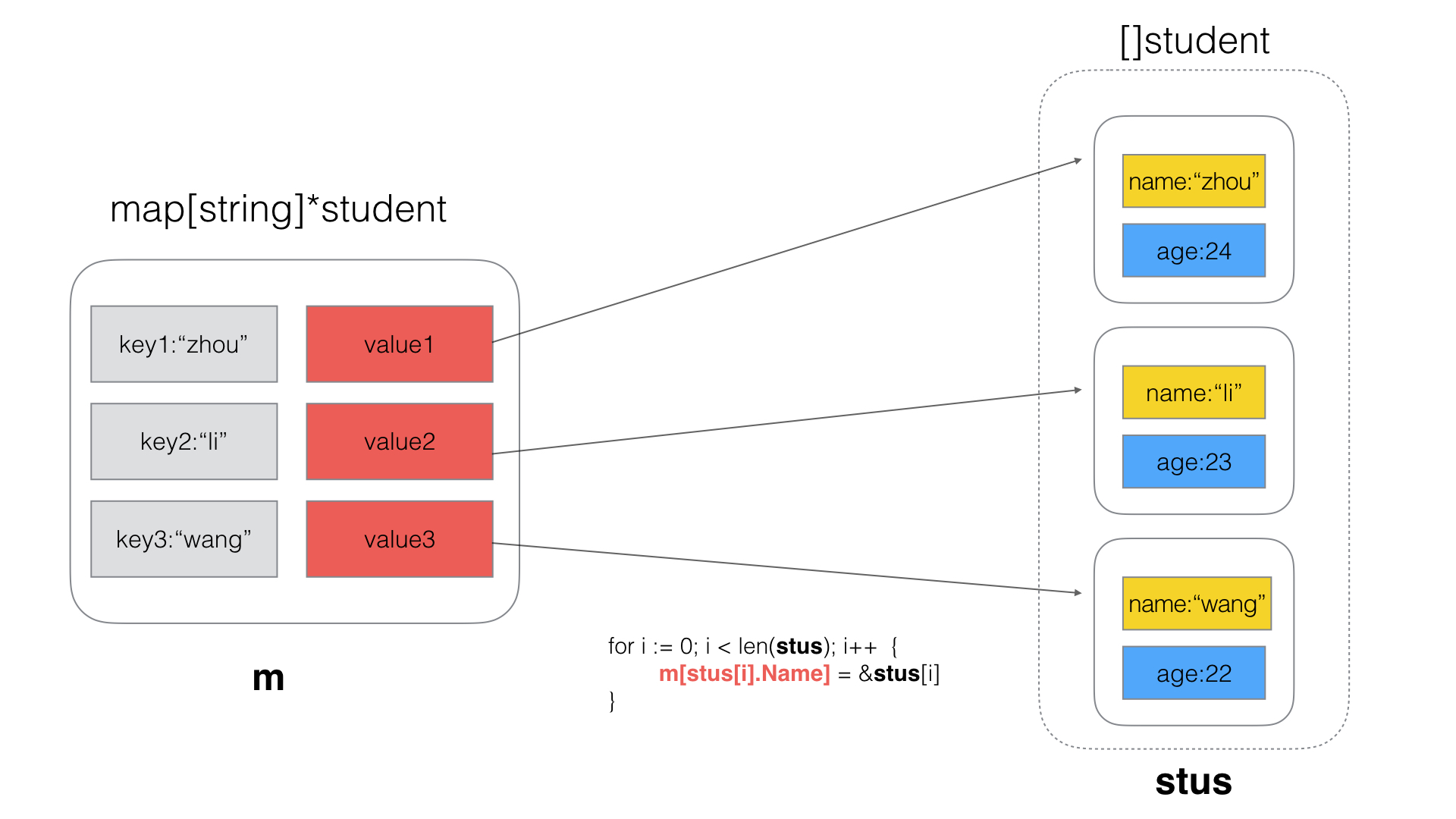
运行结果
1
2
3
|
zhou => zhou
li => li
wang => wang
|
四、interface
(1) interface的赋值问题
以下代码能编译过去吗?为什么?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
package main
import (
"fmt"
)
type People interface {
Speak(string) string
}
type Stduent struct{}
func (stu *Stduent) Speak(think string) (talk string) {
if think == "love" {
talk = "You are a good boy"
} else {
talk = "hi"
}
return
}
func main() {
var peo People = Stduent{}
think := "love"
fmt.Println(peo.Speak(think))
}
|
1、有interface接口,并且有接口定义的方法。
2、有子类去重写interface的接口。
3、有父类指针指向子类的具体对象
那么,满足上述3个条件,就可以产生多态效果,就是,父类指针可以调用子类的具体方法。
所以上述代码报错的地方在var peo People = Stduent{}这条语句, Student{}已经重写了父类People{}中的Speak(string) string方法,那么只需要用父类指针指向子类对象即可。
- 所以应该改成
var peo People = &Student{} 即可编译通过。(People为interface类型,就是指针类型)
(2) interface的内部构造(非空接口iface情况)
以下代码打印出来什么内容,说出为什么。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
package main
import (
"fmt"
)
type People interface {
Show()
}
type Student struct{}
func (stu *Student) Show() {
}
func live() People {
var stu *Student
return stu
}
func main() {
if live() == nil {
fmt.Println("AAAAAAA")
} else {
fmt.Println("BBBBBBB")
}
}
|
结果
分析:
我们需要了解interface的内部结构,才能理解这个题目的含义。
interface在使用的过程中,共有两种表现形式
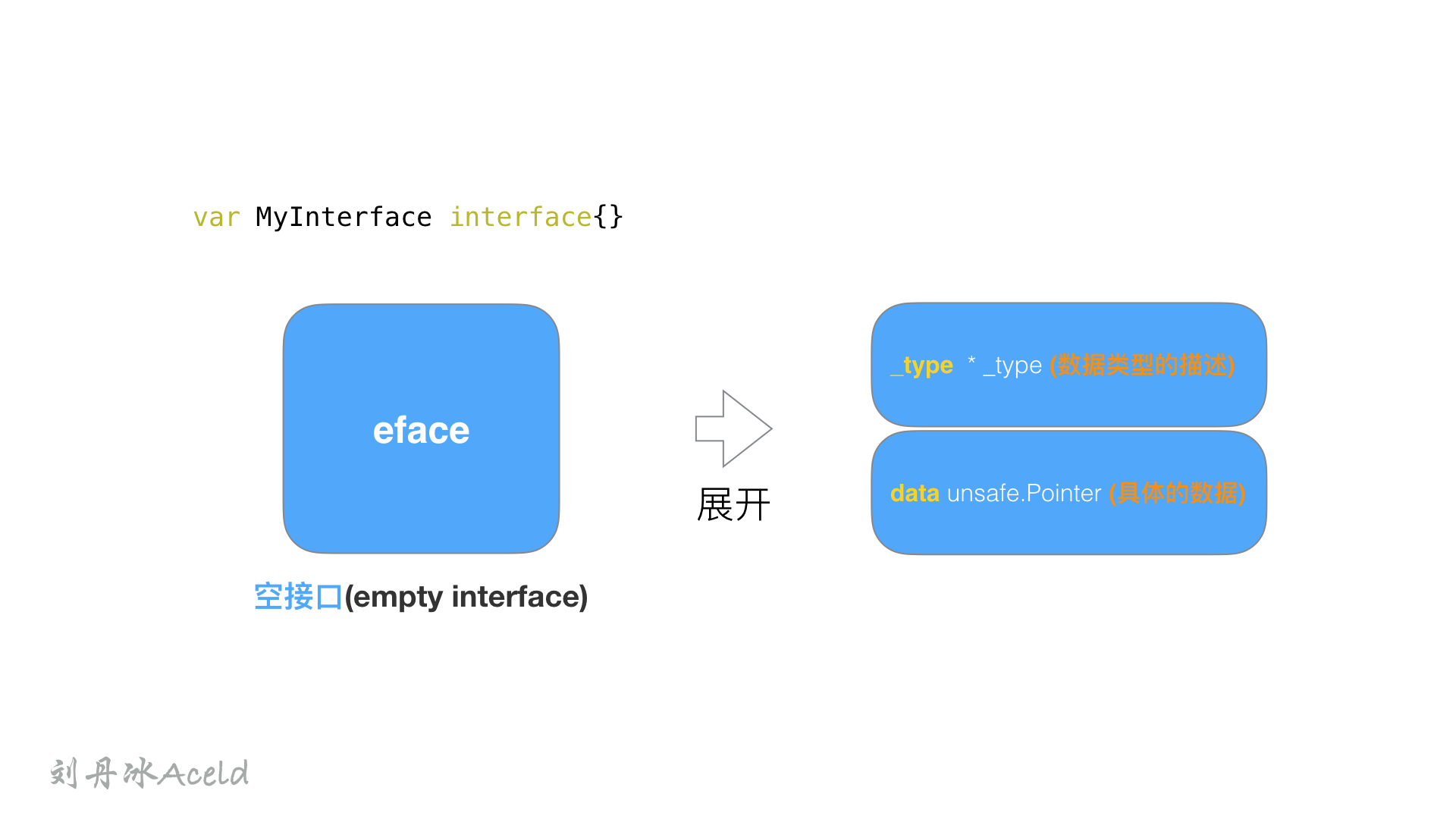
一种为空接口(empty interface),定义如下:
1
|
var MyInterface interface{}
|
另一种为非空接口(non-empty interface), 定义如下:
1
2
3
|
type MyInterface interface {
function()
}
|
这两种interface类型分别用两种struct表示,空接口为eface, 非空接口为iface.
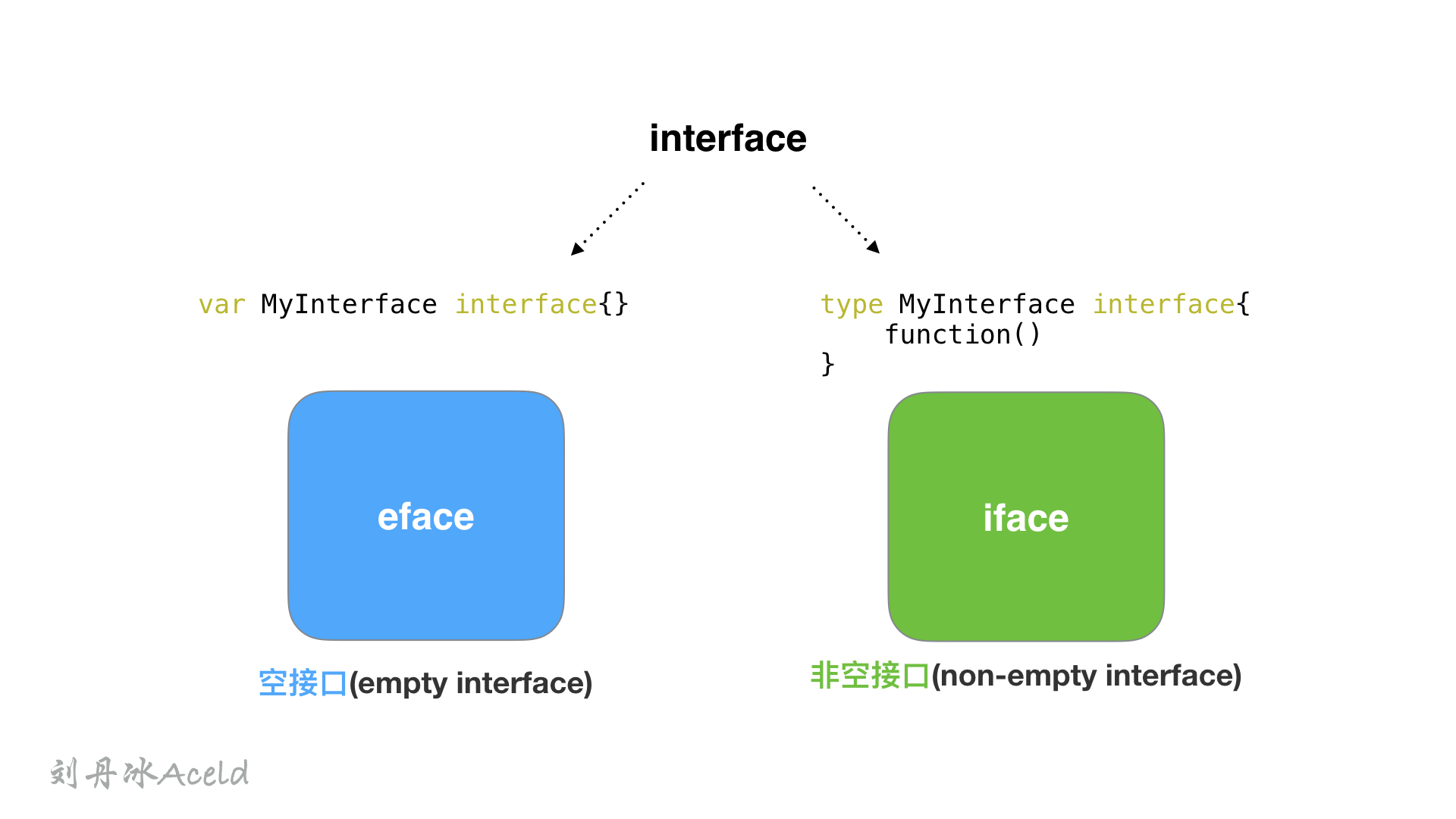
空接口eface
空接口eface结构,由两个属性构成,一个是类型信息_type,一个是数据信息。其数据结构声明如下:
1
2
3
4
|
type eface struct { //空接口
_type *_type //类型信息
data unsafe.Pointer //指向数据的指针(go语言中特殊的指针类型unsafe.Pointer类似于c语言中的void*)
}
|
_type属性:是GO语言中所有类型的公共描述,Go语言几乎所有的数据结构都可以抽象成 _type,是所有类型的公共描述,**type负责决定data应该如何解释和操作,**type的结构代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
|
type _type struct {
size uintptr //类型大小
ptrdata uintptr //前缀持有所有指针的内存大小
hash uint32 //数据hash值
tflag tflag
align uint8 //对齐
fieldalign uint8 //嵌入结构体时的对齐
kind uint8 //kind 有些枚举值kind等于0是无效的
alg *typeAlg //函数指针数组,类型实现的所有方法
gcdata *byte
str nameOff
ptrToThis typeOff
}
|
data属性: 表示指向具体的实例数据的指针,他是一个unsafe.Pointer类型,相当于一个C的万能指针void*。
非空接口iface
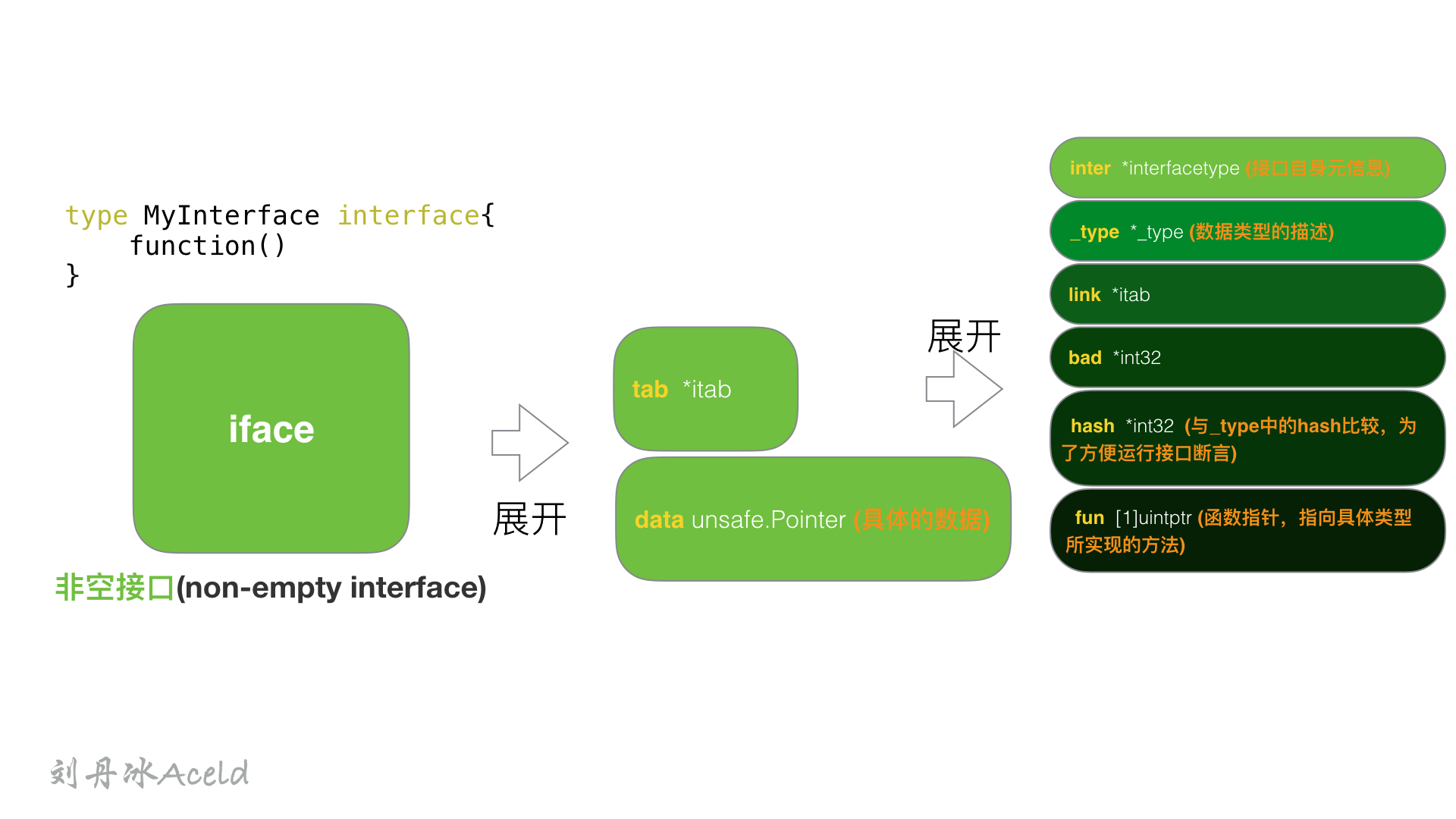
iface 表示 non-empty interface 的数据结构,非空接口初始化的过程就是初始化一个iface类型的结构,其中data的作用同eface的相同,这里不再多加描述。
1
2
3
4
|
type iface struct {
tab *itab
data unsafe.Pointer
}
|
iface结构中最重要的是itab结构(结构如下),每一个 itab 都占 32 字节的空间。itab可以理解为pair<interface type, concrete type> 。itab里面包含了interface的一些关键信息,比如method的具体实现。
1
2
3
4
5
6
7
8
|
type itab struct {
inter *interfacetype // 接口自身的元信息
_type *_type // 具体类型的元信息
link *itab
bad int32
hash int32 // _type里也有一个同样的hash,此处多放一个是为了方便运行接口断言
fun [1]uintptr // 函数指针,指向具体类型所实现的方法
}
|
其中值得注意的字段,个人理解如下:
interface type包含了一些关于interface本身的信息,比如package path,包含的method。这里的interfacetype是定义interface的一种抽象表示。type表示具体化的类型,与eface的 type类型相同。hash字段其实是对_type.hash的拷贝,它会在interface的实例化时,用于快速判断目标类型和接口中的类型是否一致。另,Go的interface的Duck-typing机制也是依赖这个字段来实现。fun字段其实是一个动态大小的数组,虽然声明时是固定大小为1,但在使用时会直接通过fun指针获取其中的数据,并且不会检查数组的边界,所以该数组中保存的元素数量是不确定的。
所以,People拥有一个Show方法的,属于非空接口,People的内部定义应该是一个iface结构体
1
2
3
|
type People interface {
Show()
}
|

1
2
3
4
|
func live() People {
var stu *Student
return stu
}
|
stu是一个指向nil的空指针,但是最后return stu 会触发匿名变量 People = stu值拷贝动作,所以最后live()放回给上层的是一个People insterface{}类型,也就是一个iface struct{}类型。 stu为nil,只是iface中的data 为nil而已。 但是iface struct{}本身并不为nil.
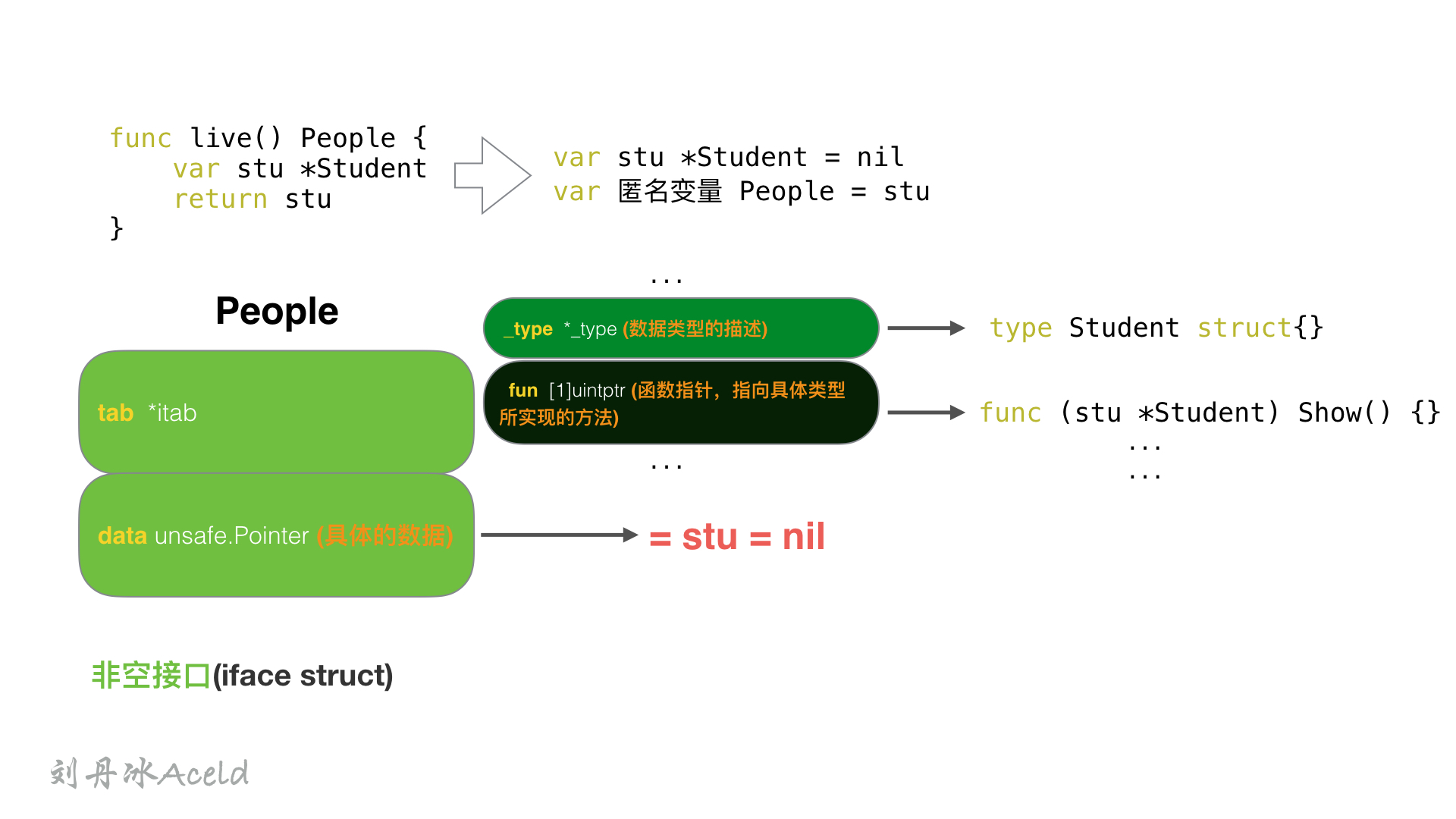
所以如下判断的结果为BBBBBBB:
1
2
3
4
5
6
7
|
func main() {
if live() == nil {
fmt.Println("AAAAAAA")
} else {
fmt.Println("BBBBBBB")
}
}
|
(3) interface内部构造(空接口eface情况)
下面代码结果为什么?
1
2
3
4
5
6
7
8
9
10
11
|
func Foo(x interface{}) {
if x == nil {
fmt.Println("empty interface")
return
}
fmt.Println("non-empty interface")
}
func main() {
var p *int = nil
Foo(p)
}
|
结果
分析
不难看出,Foo()的形参x interface{}是一个空接口类型eface struct{}。
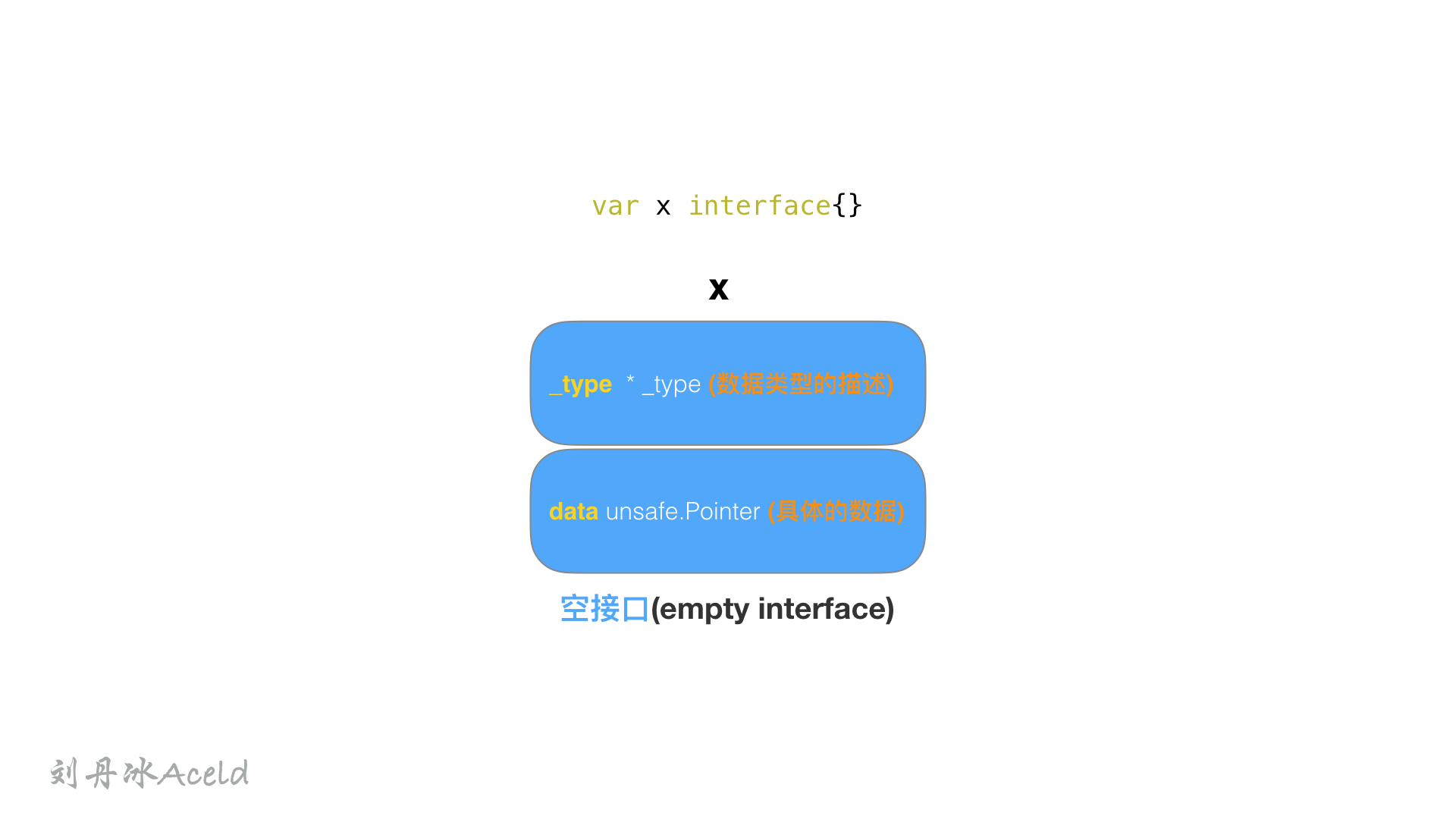
在执行Foo(p)的时候,触发x interface{} = p语句,所以此时 x结构如下。
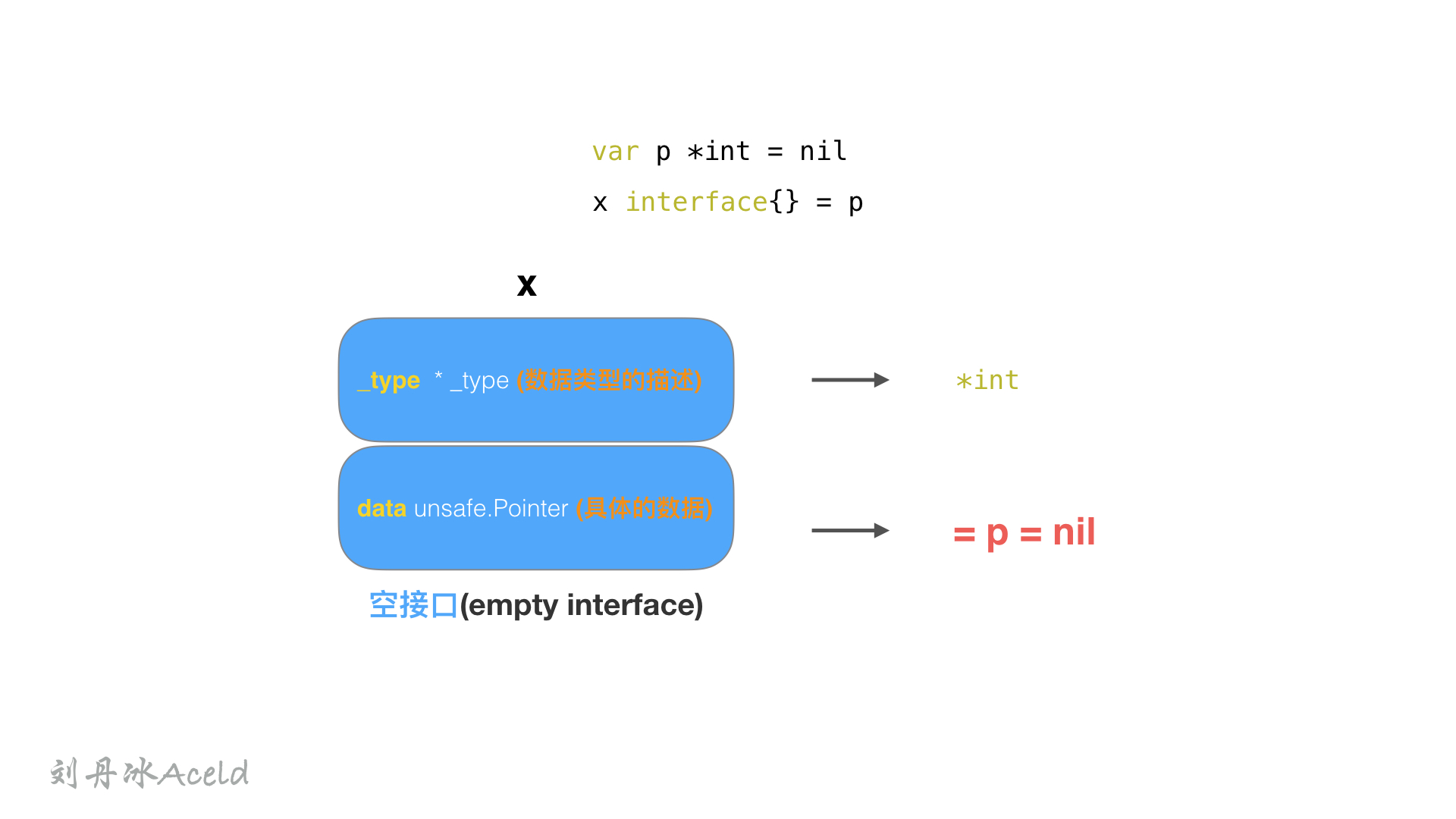
所以 x 结构体本身不为nil,而是data指针指向的p为nil。
(4) inteface{}与*interface
ABCD中哪一行存在错误?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
type S struct {
}
func f(x interface{}) {
}
func g(x *interface{}) {
}
func main() {
s := S{}
p := &s
f(s) //A
g(s) //B
f(p) //C
g(p) //D
}
|
结果
1
2
3
4
5
6
|
B、D两行错误
B错误为: cannot use s (type S) as type *interface {} in argument to g:
*interface {} is pointer to interface, not interface
D错误为:cannot use p (type *S) as type *interface {} in argument to g:
*interface {} is pointer to interface, not interface
|
五、channel
(1)Channel读写特性(15字口诀)
首先,我们先复习一下Channel都有哪些特性?
- 给一个 nil channel 发送数据,造成永远阻塞
- 从一个 nil channel 接收数据,造成永远阻塞
- 给一个已经关闭的 channel 发送数据,引起 panic
- 从一个已经关闭的 channel 接收数据,如果缓冲区中为空,则返回一个零值
- 无缓冲的channel是同步的,而有缓冲的channel是非同步的
以上5个特性是死东西,也可以通过口诀来记忆:“空读写阻塞,写关闭异常,读关闭空零”。
执行下面的代码发生什么?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
package main
import (
"fmt"
"time"
)
func main() {
ch := make(chan int, 1000)
go func() {
for i := 0; i < 10; i++ {
ch <- i
}
}()
go func() {
for {
a, ok := <-ch
if !ok {
fmt.Println("close")
return
}
fmt.Println("a: ", a)
}
}()
close(ch)
fmt.Println("ok")
time.Sleep(time.Second * 100)
}
|
15字口诀:“空读写阻塞,写关闭异常,读关闭空零”,往已经关闭的channel写入数据会panic的。因为main在开辟完两个goroutine之后,立刻关闭了ch, 结果不唯一:
1
2
|
// 第二个协程中的打印有可能输出
panic: send on closed channel
|
六、WaitGroup
(1) WaitGroup与goroutine的竞速问题
编译并运行如下代码会发生什么?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
package main
import (
"sync"
//"time"
)
const N = 10
var wg = &sync.WaitGroup{}
func main() {
for i := 0; i < N; i++ {
go func(i int) {
wg.Add(1)
println(i)
defer wg.Done()
}(i)
}
wg.Wait()
}
|
结果
1
|
结果不唯一,代码存在风险, 所有go未必都能执行到
|
这是使用WaitGroup经常犯下的错误!请各位同学多次运行就会发现输出都会不同甚至又出现报错的问题。 这是因为go执行太快了,导致wg.Add(1)还没有执行main函数就执行完毕了。 改为如下试试
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
package main
import (
"sync"
)
const N = 10
var wg = &sync.WaitGroup{}
func main() {
for i:= 0; i< N; i++ {
wg.Add(1)
go func(i int) {
println(i)
defer wg.Done()
}(i)
}
wg.Wait()
}
|

 支付宝
支付宝